Simplify Grouping with 'Group By All' in Databricks
Author: Muhamamd Umar Amanat
: 28th September 2023

: 28th September 2023
Photo by Martin Sanchez on Unsplash
While analyzing our data we often used "group by" to aggregate our data and get valuable insight from it. "Group by"
clause is one of the widely used clauses for aggregating our data.
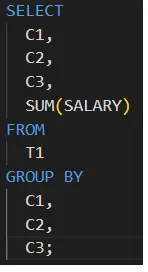
To understand better let's take a simple scenario where I have to do "sum" aggregation on groups of column names as c1, c2, and c3 from table t1 as shown below.
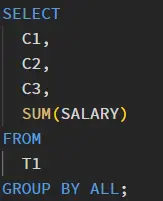
Above 'group by' can be replaced easily by 'group by all' and this will do the same but with minimal and readable code.
This is depicted in Figure 2.
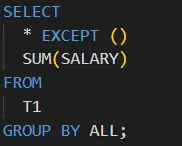
There is another syntax alternate to the code shown in Figure 2. with the same functionality. This syntax is kind of more explicit
as shown in Figure 3.
Why "Group by All"?
The first question that came to mind is why to use "group by all" when there is already a "group by" clause present in Spark.To understand better let's take a simple scenario where I have to do "sum" aggregation on groups of column names as c1, c2, and c3 from table t1 as shown below.
Figure 1. Group by in Databricks, Source: Author
Figure 2. 'Group by all' in Databricks, Source: Author
Figure 3. 'Group by all with except' in Databricks, Source: Author
Advantage
Well 'group by all' has a few advantages as listed below:- - No need to specify every column.
- - Remove repetitive columns or fields from query
- - The feature automatically aggregates using all non-aggregated fields from the select list 1